What is IBM InfoSphere Optim Data Privacy and use cases of IBM InfoSphere Optim Data Privacy?
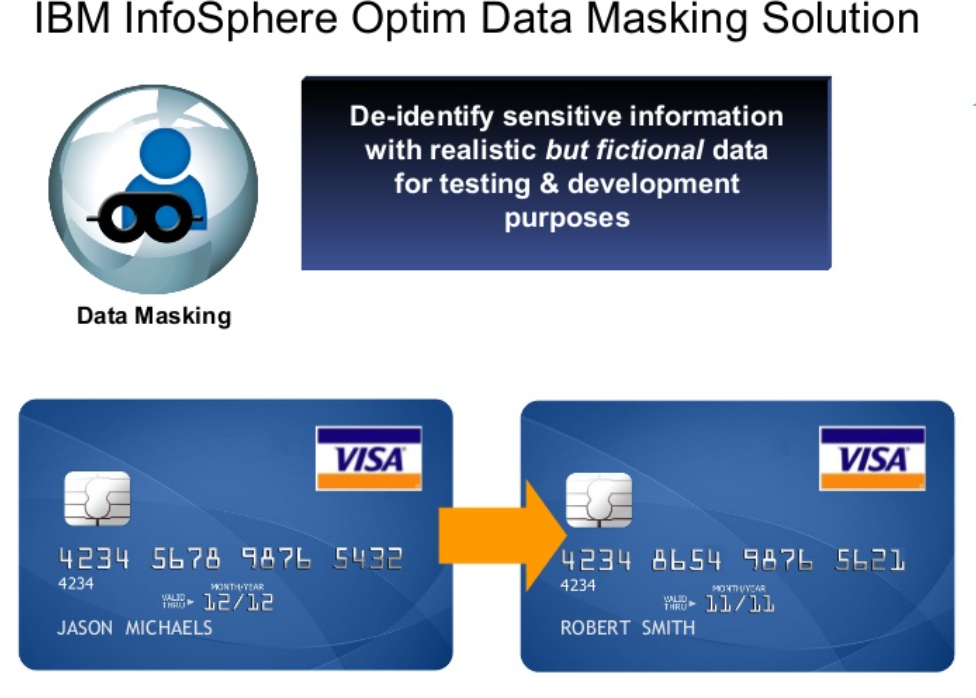
IBM InfoSphere Optim Data Privacy is a data privacy solution that helps organizations protect sensitive information by masking, de-identifying, and anonymizing data while maintaining its usability for development, testing, and analytics purposes. It allows organizations to comply with data privacy regulations and policies by ensuring that sensitive data is not exposed during non-production activities.
Top 10 Use Cases of IBM InfoSphere Optim Data Privacy:
- Non-Production Environments: Masking sensitive data in non-production environments ensures that developers and testers work with realistic data without exposing confidential information.
- Outsourcing and Offshoring: When sharing data with third-party vendors or offshore teams, data privacy measures can be applied to prevent data exposure.
- Analytics and Reporting: Anonymize data before performing data analytics, ensuring that personally identifiable information (PII) remains protected.
- Regulatory Compliance: Help organizations meet data privacy regulations like GDPR, HIPAA, and others by ensuring that sensitive data is properly protected.
- Security Testing: De-identify data to conduct security testing without compromising real user information.
- Data Warehousing: Use masked data in data warehousing projects to maintain data privacy while supporting reporting and analysis.
- Application Development: Developers can work with masked data that closely resembles production data, improving application quality without exposing real data.
- User Training: Anonymized data can be used for user training, ensuring that employees are trained without accessing actual sensitive data.
- Cloud Migration: Prepare data for migration to the cloud by de-identifying sensitive information.
- Research and Collaboration: Share data for research or collaborative purposes while ensuring privacy and compliance.
What are the feature of IBM InfoSphere Optim Data Privacy?

- Data Masking: Apply various masking techniques to replace sensitive data with realistic but non-identifiable values.
- Data Subsetting: Create smaller, representative subsets of data for development and testing purposes.
- Data Anonymization: Transform data into an anonymous format while maintaining its usefulness for analysis.
- Policy-Based Masking: Apply data masking rules based on predefined policies and rulesets.
- Data Discovery: Identify sensitive data across your environment and classify it for appropriate masking.
- Automation: Automate the masking and data privacy processes to reduce manual effort.
- Auditing and Tracking: Maintain an audit trail of data privacy activities for compliance purposes.
How IBM InfoSphere Optim Data Privacy works and Architecture?
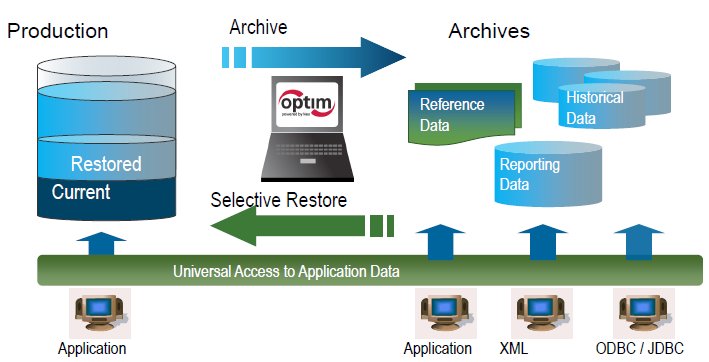
IBM InfoSphere Optim Data Privacy integrates with various data sources, such as databases, files, and applications. It uses masking and anonymization techniques to modify sensitive data while preserving referential integrity. The solution typically consists of the following components:
- Data Source Connectors: These connectors establish connections to various data sources, enabling data extraction and masking.
- Data Masking Engine: This engine applies masking algorithms to sensitive data based on predefined rules and policies.
- Data Repository: Stores masking rules, policies, and metadata related to the masking process.
- Reporting and Auditing: Provides reporting on masking activities and maintains an audit trail for compliance purposes.
How to Install IBM InfoSphere Optim Data Privacy?
Please note that the installation process can vary based on your environment, version, and specific requirements. It’s important to consult the official documentation for the most accurate and up-to-date installation instructions. Generally, the installation process includes these steps:
- Prerequisites: Review and fulfill the hardware and software prerequisites specified in the product documentation.
- Installation: Run the installer and follow the on-screen prompts to install the IBM InfoSphere Optim Data Privacy software.
- Configuration: Configure connection settings for data sources, masking rules, and policies.
- Licensing: Apply the appropriate license keys to enable the full functionality of the software.
- Integration: Integrate with your existing data sources and tools as needed.
- Testing: Verify that the installation and configuration were successful by performing test masking operations.
- Documentation: Keep thorough documentation of the installation process, configuration settings, and any customizations made.
Always refer to the official IBM InfoSphere Optim Data Privacy documentation and support resources for detailed installation instructions tailored to your specific environment.
Basic Tutorials of IBM InfoSphere Optim Data Privacy: Getting Started
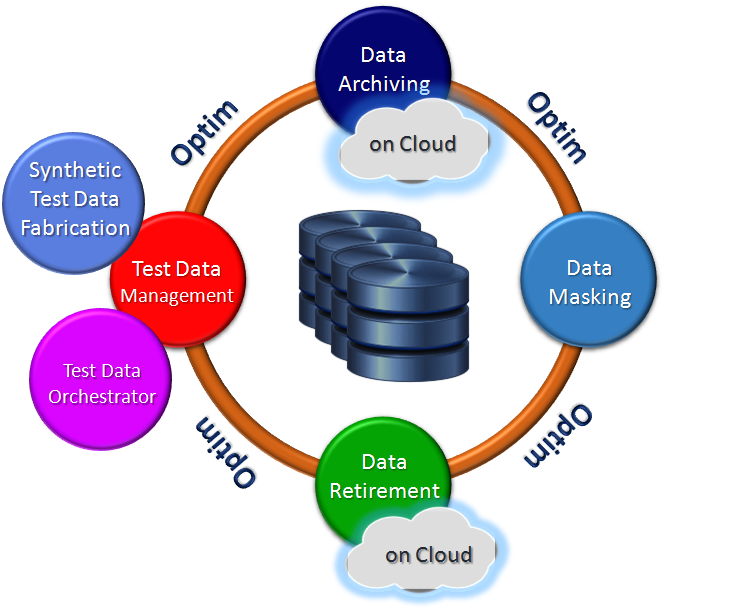
Creating a comprehensive step-by-step tutorial for IBM InfoSphere Optim Data Privacy involves a lot of detail and can vary depending on the specific version and your environment. However, I can provide you with a basic outline to help you get started.
Step 1: Installation and Setup:
- Prerequisites: Ensure your environment meets the hardware and software requirements for IBM InfoSphere Optim Data Privacy.
- Software Installation: Install the IBM InfoSphere Optim Data Privacy software following the provided installation guide.
- Licensing: Apply the appropriate license keys to activate the software.
Step 2: Connect to Data Sources:
- Configure Data Sources: Set up connections to your data sources, such as databases or flat files, where sensitive data is stored.
- Define Data Models: Define the data models that describe the structure of your data sources. This helps the tool understand the relationships between tables and columns.
Step 3: Define Masking Rules:
- Create Rulesets: Define rulesets that contain masking rules for specific types of data. For example, you might have rulesets for Social Security Numbers, names, addresses, etc.
- Define Masking Algorithms: Within each ruleset, define the masking algorithms you want to use, such as randomization, substitution, or shuffling.
Step 4: Create and Test Data Privacy Projects:
- Create a Project: Set up a new data privacy project and specify the source and target data sources.
- Select Columns: Choose the columns you want to mask in the source data.
- Apply Rulesets: Apply the appropriate rulesets and masking algorithms to the selected columns.
- Preview and Test: Preview the masked data to ensure the masking rules are applied correctly and the data retains its integrity.
Step 5: Execution and Reporting:
- Execute the Masking Process: Run the data privacy project to mask the sensitive data in your source data sources.
- Monitor Progress: Monitor the progress of the masking process and address any issues that arise.
- Generate Reports: Generate reports that document the masking activities, showing what data was masked and how.
Step 6: Validation and Verification:
- Verify Masked Data: Access the target data sources to verify that the sensitive data has been masked properly.
- Perform Testing: Use the masked data in testing and development environments to ensure it retains its usability.
Step 7: Scheduling and Automation:
- Automation: Set up automation for regular data masking processes, ensuring that sensitive data is consistently protected.
Step 8: Documentation and Training:
- Documentation: Document your data privacy projects, masking rules, and configurations for future reference and auditing.
- Training: Train your team on how to use IBM InfoSphere Optim Data Privacy effectively.
Remember, this is a simplified overview, and actual implementation may involve additional steps and considerations. Always consult the official IBM InfoSphere Optim Data Privacy documentation and resources for accurate and detailed instructions.
